简单总结下redis的哨兵机制
哨兵机制是什么
哨兵就是一台运行在特殊状态的redis服务器, 用来监控master节点和slave节点以及其他sentinel节点的状态, 在master节点下线时, 从slave节点中选择新的master节点
解决了什么问题
解决了redis服务端的高可用, 即master节点宕机之后, 自动切换slave节点来继续提供服务
不能解决什么问题
- 不能解决的数据不丢失的问题, 就是在master节点宕机时, 因为master同步数据到slave是异步同步的方式, 所以是有时间差的,在这个时间差内更新的数据会丢失掉
怎么启动哨兵服务
- 有两种方式启动哨兵服务
$ redis-sentinel /path/to/your/config/sentinel.conf$ redis-server /path/to/your/config/sentinel.conf —-sentinel
- 有两种方式启动哨兵服务
启动过程
初始化服务器
将普通redis服务端的代码替换为sentinel模式的代码
初始化sentinel状态
根据配置, 初始化sentinel监控的主服务器列表
创建连向主服务器的连接
会创建两个连接,
一个是命令连接, 用于向服务器发送命令
一个是专门订阅服务器的
__sentinel__:hello频道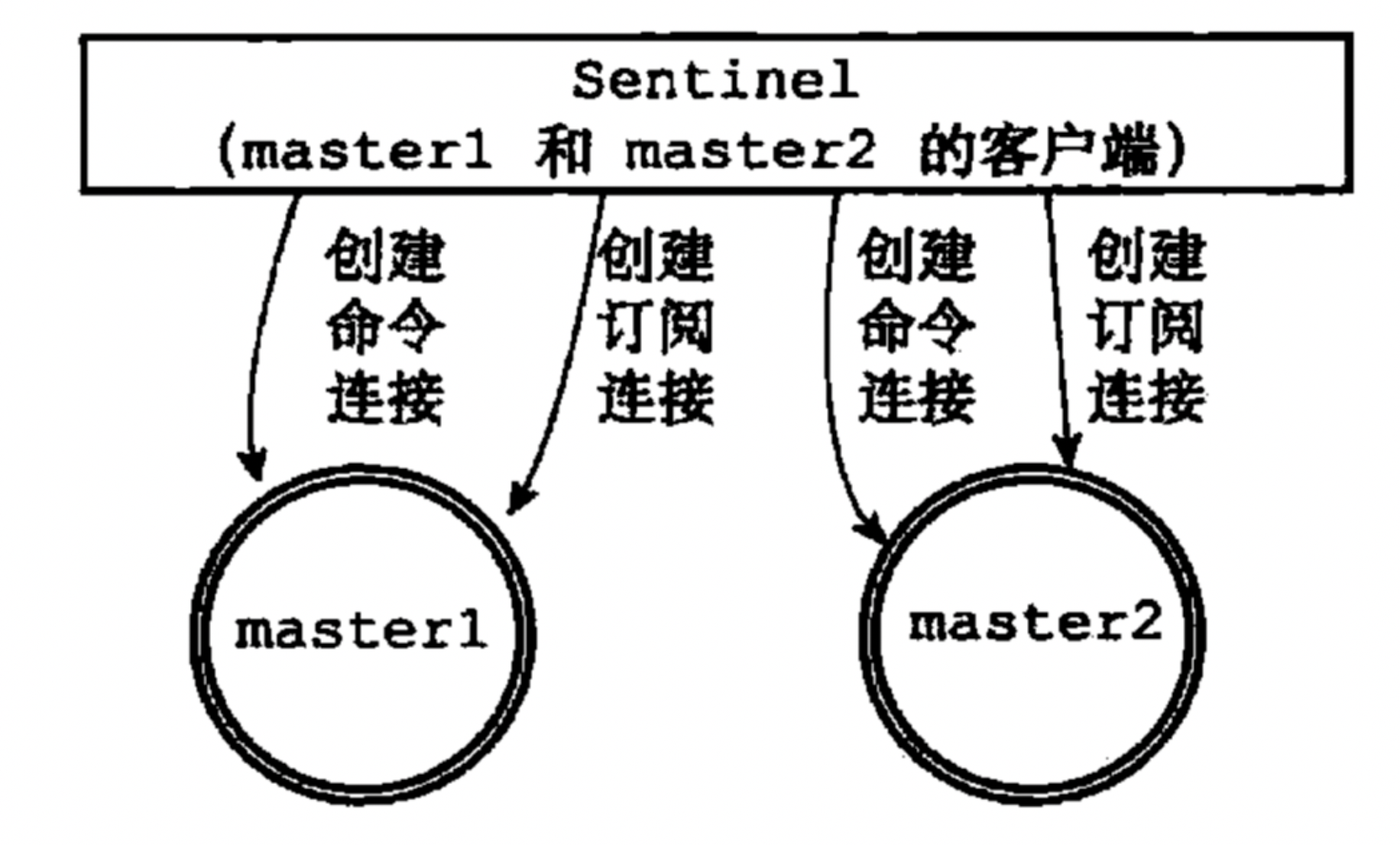
工作过程
获取各种服务器的状态并建立相应的连接
获取主服务器的信息,并建立命令连接和订阅连接
- 默认情况下, 哨兵每10s通过命令连接向服务器发送INFO命令,并通过响应信息获取到服务器的状态
- 一个是可以获得服务器本身的信息比如runid和服务器的角色
- 另外就是还可以获取从服务器的信息
- 比如从服务器的hostname, ip, port等等
- 默认情况下, 哨兵每10s通过命令连接向服务器发送INFO命令,并通过响应信息获取到服务器的状态
获取从服务器的信息,并建立命令连接和订阅连接
- 当sentinel从主服务器那里获取到了新的从服务器, 会创建对应的从服务器的实例对象信息
- 同时也会向从服务器创建两个链接
- 命令连接和订阅连接, 作用和主服务器的两个连接一致
- 也是每10秒就像命令连接发送一个INFO命令, 并根据响应信息解析出从服务器的状态
- 包括从服务器本身的一些信息,比如runid, 角色
- 主服务器的hostname, ip, port等
- 从服务器和主服务器间的连接的状态
- 从服务器的优先级
- 从服务器复制的偏移量
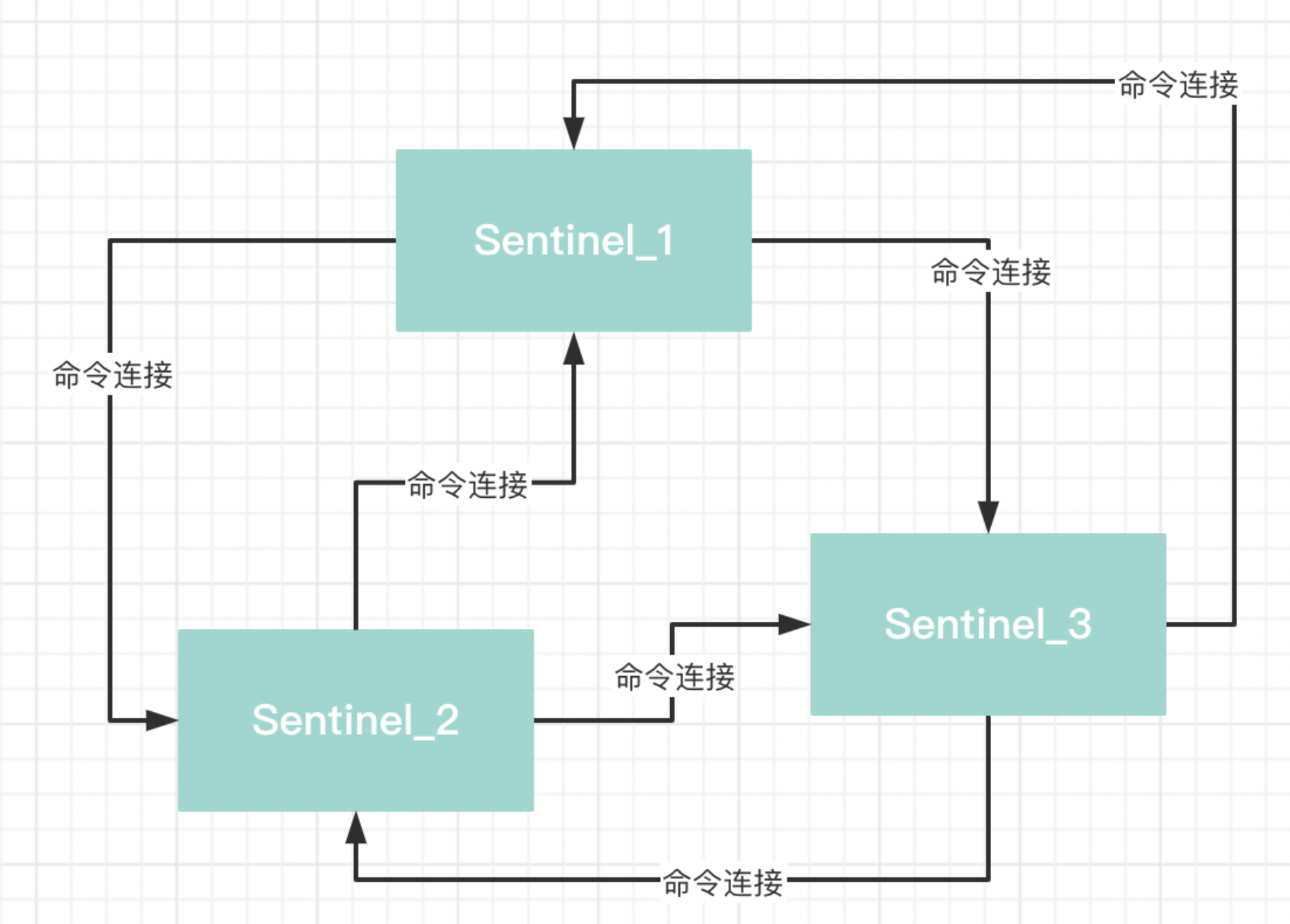
获取其他sentinel服务的信息, 并互相创建命令连接
- sentinel每2秒向主服务器和从服务器发送命令
- 向__sentinel __:hello频道内发送信息, 包含当前sentinel信息和master的信息
- 同时在订阅连接上就可以接受到这个频道上面的所有信息, 就可以解析出其他的sentinel的信息了
- 在解析到其他sentinel信息的时候, 在服务器内部创建sentinels的实例信息
- 同时还向其他sentinel创建一个命令连接
- 同时其他的sentinel也会和当前的这个sentinel实例创建一个命令连接
- sentinel每2秒向主服务器和从服务器发送命令
监测服务主观下线状态(SDOWN)
- sentinel服务每1秒会通过命令链接, 向所有的实例(主节点, 从节点, 其他sentinel节点)发送PING 命令
- 然后根据响应信息判断响应内容是否有效
- 有效回复为响应内容为: PONG, LOADING, MASTERDOWN三种
- 无效响应为除有效响应的三种外,其他响应内容都是无效的, 包括超时未响应
- 然后对于无效响应, 判断服务否是进入主观宕机
- 如服务在指定时间内未响应过有效信息, 则会判断该实例为主观宕机
- 通过#Redis参数
down-after-milliseconds来设置该时间- 这个参数是设置在sentinel端的, 在sentinel内, 判断主服务器,从服务器,其他sentinel服务,主观宕机都是用的这一个参数
- 另外就是监控同一个master的其他sentinel设置的时间是不一致的, 所以有可能sentinel1任务master1已经宕机了, 但是sentinel2因为设置的时间比较长, 还没有任务该master1已经宕机
- 通过#Redis参数
- 如服务在指定时间内未响应过有效信息, 则会判断该实例为主观宕机
监测服务客观下线状态(ODOWN)
在sentinel检测到一个服务已经主观宕机, 这个时候, 该sentinel会通过命令连接向其他的sentinel进行询问, 判断其他sentinel服务是否也认为该节点实例也下线了
发送
SENTINEL is-master-down-by-addr ip port current_epoch runid命令到其他的sentinel服务
响应
SENTINEL is-master-down-by-addr查询命令
根据响应结果判断是否满足客观下线状态
- 判断认为当前master节点已经主观下线了的数量是否大于等于配置中
quorum设置的数量- 设置方式为
sentinel monitor master 127.0.0.1 6379 2 - 这里这个quorum在每个sentinel中设置的也是可能不一样的, 比如在sentinel1中设置的是2, 那么只要有其他任何一个sentinel也认为这个节点主观下线了, 那么这个master在该sentinel1上就会设置为客观下线, 但是在sentinel5上面设置的quorum设置的是5, 那么在sentinel5上, 这个master节点就不满足客观下线的条件
- 设置方式为
- 如果大于这个数量,则设置当前master节点为客观下线状态, 更新sentinel服务中测个实例的状态为ODOWN
- 判断认为当前master节点已经主观下线了的数量是否大于等于配置中
选举sentinel leader
- 在某个sentinel认为某个master已经客观下线后, 需要选择新的master节点来继续服务, 在这之前需要先在众多sentinel中选择一个leader来执行故障迁移
- 选举规则采用的是Raft协议中的leader选举算法
- 每个sentinel都有可能成为leader
- 每一轮选举
configuration epoch都会自增- 这个就是raft协议中的任期号
- 参选的sentinel向其他sentinel服务发送 is-master-down-by-addr 命令, 其中runid参数部分由*改为这个sentinel服务的runid
故障转移
- 在选举出leader sentinel后, 由这个leader执行故障转移过程
- 从已下线的master服务的slave服务中选择一个作为新的master节点
- 获得slave服务的列表
- 删除已经下线了的slave服务
- 保证slave服务状态是正常的, 总不能选举出来一个已经下线了的slave服务作为新的master节点吧
- 删除最近5秒内没有回复过该sentinel INFO命令的slave服务
- 继续保证剩下的slave存活的可能下更大
- 删除和已下线的master节点断开时间超过 down-after-milliseconds * 10 时间的slave服务
- 保证剩下的服务, 数据是比较新的, 如果早早就和master断开了, 则说明数据可能是比较老的了, 很久没有复制了
- 对剩下的slave服务根据优先级进行排序
- 对于优先级相同的, 再根据已复制的偏移量进行排序
- 偏移量越大, 说明数据越新, 则优先级就越高
- 向选中的slave 发送
SLAVEOF no one命令, 通知这个slave切换为master模式- 在发送过 SLAVEOF no one命令后, sentinel leader会每隔1s发送INFO命令, 并观察返回的结果
- 如果返回角色为master, 则说明这个slave已经成功切换成master模式
- 在发送过 SLAVEOF no one命令后, sentinel leader会每隔1s发送INFO命令, 并观察返回的结果
- 让其他slave服务开始复制新的master
- 向其他从服务器发送 SLAVEOF命令, 让他们开始复制新的master服务器
- 将已经下线的master节点设置为slave节点
- 因为原先master节点现在已经下线了, 所以先把状态保存在sentinel服务内, 在该节点上线后, sentinel再发送SLAVEOF 命令, 让它复制新的master节点
最佳实践
由Raft协议可以知道, sentinel服务实例需要设置基数个, 且最少需要启动三个服务
总结
- sentinel只是一个运行在特殊模式下的redis服务
- 根据配置监测的master节点,进而发现该master的slave服务列表,和其他的sentinel服务实例
- 和master/slave服务分别建立命令连接和订阅链接, 和其他sentinel服务实例互相建立一个命令连接
- 通过INFO命令获取master/slave服务的信息和状态等
- 通过订阅
__sentinel__:hello频道发现到其他的sentinel实例 - sentinel每1s向其他服务实例发送ping命令, 并根据响应信息判断是否是主观下线
- 如果监测到一个master主观下线, 则开始监测是否为客观下线
- 客观下线后, 可是sentinel leader选举
- 有sentinel leader 执行故障转移